百家樂IOS/安卓通用版/手機APP下載 MiniMax M3一手實測:老黃PPT上74個Logo,我以為能難住它
MiniMax M3 一會兒上線后,Token Plan 的新計費風景也引起了熱議。
眾說紛繁之下,MiniMax 官方也火速復興,提高了周用量名額,并對以前莫得周名額的老用戶保抓了這個設定。

但價錢爭議以外,更值得咱們海涵的,依然是模子智商。
全球樹立者,也都在海涵模子智商和工夫。
比如 Hermes 框架的樹立平臺 Nous Research 的聯創,就公開在 X 上給 M3 背書。

還有 Vercel CEO、GitHub 540k 星 AI 大佬 Guillermo Rauch,也在 X 上公開保舉 MiniMax M3,稱它的露出緊跟 Opus 和 GPT-5,但價錢只好其盡頭之一。
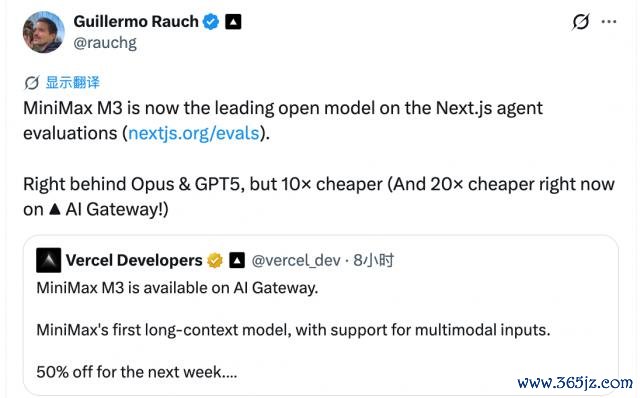
至于模子的踐諾任務露出,官方一共給了三個 Demo ——復刻論文、優化 CUDA 算子,還有我方考試模子。
我也我方上手,讓 M3 嘗試了一些清新玩法。
不管是官方 Demo 如故我我方的測試,想完成這些任務,長崎嶇文、多模態、Coding 三個智商得同期在線才行。
而 M3,是國內第一個把這三件事同期作念到的開源模子。
就算在閉源模子當中,能作念到的也就只好"御三家"(GPT、Claude、Gemini)的最新旗艦。
M3 給出的獲利是,SWE-Bench Pro 上跑出 59%,跳動 GPT-5.5 和 Gemini 3.1 Pro,接近 Opus 4.7。
何況 M3 效能更高,1M 崎嶇文下每 token 計較量壓到上代的 1/20,decoding 實測加快跳動 15 倍。
同期,為了搭配 M3,MiniMax 此次還同步推出了 MiniMax Code。
這是個專為 M3 遐想、并與 M3 一齊考試的 Harness,對標的便是 Vibe Coding 客戶端里的扛把子 Claude Code。
既然如斯,那就徑直模子框架一齊測,用 MiniMax Code 來望望 M3 的露出究竟若何。
一手實測 MiniMax M3
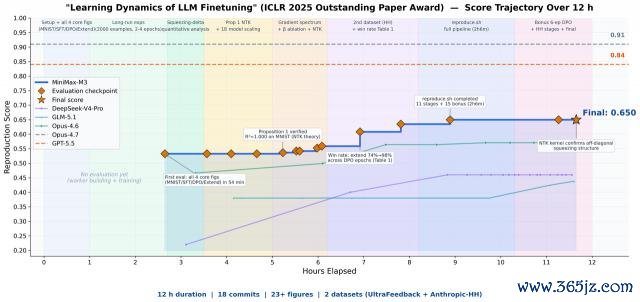
官方 Demo 里,有東談主把一篇 ICLR 2025 的論文扔給它,讓它寥寂復現,限度 M3 連氣兒運行 12 小時后班師委派限度,全程莫得任何輔助。
這是一篇 Outstanding Paper Award 獲獎論文,接洽的是大模子微調歷程中的學習能源學。
具體來說,論文的中樞是用"學習動態"框架救援解釋大模子微調中的反直觀氣候,該框架將每步梯度更新剖析為三個因子,揭示了更新若何通過樣本相似性在不同輸出之間傳播。
基于此,論文提議在 SFT 階段同期考試 y ?,讓負樣本提前"離開低概率區域",從根源上緩解擠壓效應。

這個任務中,M3 自主運行接近 12 小時,產出 18 次 commit 與 23 張實驗圖表。
它不僅跑通了中樞實驗,班師吻合了 SFT 階段的展望概率變化趨勢,還明晰不雅測到 DPO 實驗重心商議的擠壓效應,并到手考證了原論文提議的 Extend 緩解范例。
半途碰到跑欠亨的實驗,它會我方進行會診,碰到限度對不上的地點就我方退換,通盤歷程耐久莫得東談主工介入。
我也膠柱鼓瑟,找了一篇 ICLR 2026 的論文讓它復現。
這篇論文處治的是考試大模子時會碰到的一個底層問題。

Muon 是最近很火的優化器,它每一步更新權重之前,需要對梯度矩陣作念一次矩陣極剖析。
經典作念法是用 Newton-Schulz 迭代,每步套一個固定的五次多項式,淺顯但管制慢。
這篇論文提議的 Polar Express,把固定所有換成了動態求解,即每一輪說明現時矩陣的奇異值畛域,現場算出本輪表面最優的多項式所有。

M3 把通盤兌現拆成了三個模塊,包括 baseline 范例、最優多項式求解器,以及主算法骨子。

其中最有含金量的是求解器,它從等波動條目動身,建線性方程組,迭代求解,我方算出一組所有。
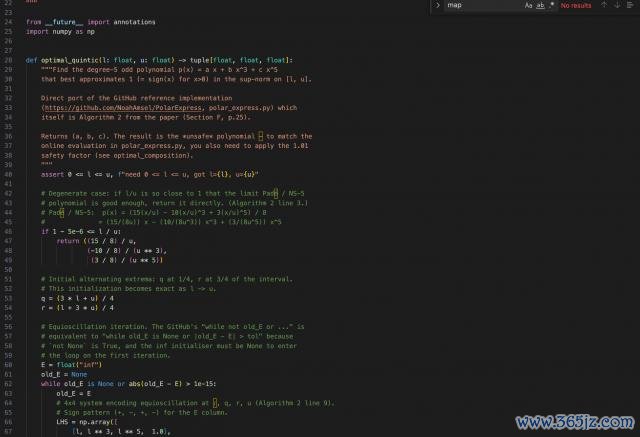
然后它有意畫了一張考證圖,把我方從零推算出來的所有,和論文里硬編碼的數字比肩放在一齊,八個迭代要領一一比對。
限度就像底下這張圖,兩條線簡直完全類似,各異肉眼不可見。
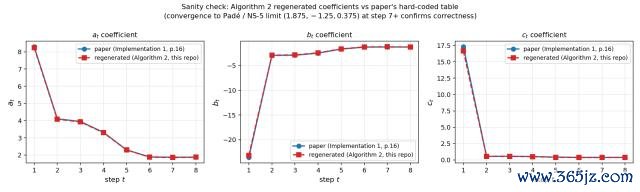
這張圖本人便是最佳的復現講解,評釋 M3 寥寂走了一遍和論文作家疏通的推導旅途,得到了疏通的謎底。
除了論文,我還用 M3 玩出了更多新項目。
這不是老黃前一陣子來北京打卡了南鑼飽讀巷嗎,其時量子位還有意作念過一期探店著作。
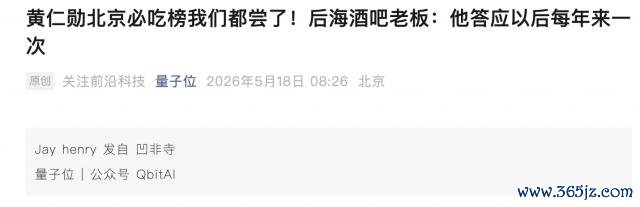
于是我就想,能弗成讓 M3 按照老黃的行程,作念一個打卡輿圖呢。
天然那篇著作我是沒喂給 M3 看的,因為我想望望,它能弗成憑借我方的力量,把這些信息征集到。
Prompt 就這一句:
搜一下黃仁勛最近一次來北京都打卡了哪些好意思食,利用真實輿圖制作可交互的一個打卡攻略網頁
真話實說,這個任務我一運行并莫得抱太大但愿,倒不是說這個任務有多難,是我以為 M3 可能會卡在獲取輿圖資源這一步。
但我沒料想,還真有免費的輿圖樹立資源不錯徑直獲取,何況還被 M3 發現了。
它先征集了蟻集上的信息,然后追思出了老黃去過的打卡點,然后搜索他們在輿圖上的坐標,決定利用 Leaflet(一個用于構建 Web 輿圖的開源 JS 庫)和高德輿圖瓦片為中樞器具來完成我的這個任務。

最終呢,M3 亦然班師把老黃去過的 9 個好意思食打卡點,都艷麗在了輿圖上。
亞搏體育中國一站式服務官網交互頁面支抓深廣輿圖和衛星輿圖兩種模式,點擊交互也透徹正常。
這里多一句嘴,其實老黃那天去的地點有 11 個,但財神廟和拓意玩物店不屬于我領導詞里說的"好意思食",是以 M3 的操作是正確的。
來看下一個任務。
既然前一個任務還是利用上老黃了,那就再讓他發光發燒一次。
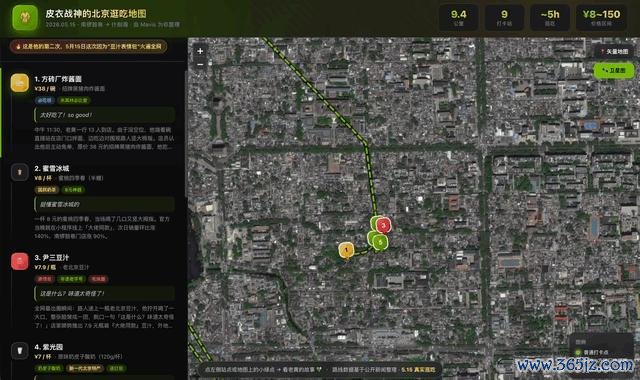
就在昨天的 ComputeX 上,黃仁勛發表了演講,其間就提到了" DSX AI 工場生態系統"。
講到這里的時刻,老黃放了這么一張 PPT。

這一輪,我頂住給 M3 的任務便是把 PPT 里的這 74 家(我躬行數過)企業的而已透徹找到,匯總作念成一個交互式網頁。
領導詞長這么:
這張圖是黃仁勛在 ComputeX 上先容的 DSX AI 生態系統廠商名單,征集整個這些廠商的信息,制作一個橫向的瀑布流網頁,點擊其中的卡片融會公司先容。

到這里我依然有些記憶,70 多個公司,用的還全是 Logo,不知談 M3 能弗成看得過來,歸正我還是很暈了。
但經過我硬著頭皮仔細查對,M3 找到的這 74 家公司無一例外透徹正確。

有了公司名單之后,便是征集這些公司的而已并遐想網頁了,最終 M3 亦然班師完成了這項任務。
徑直看后果,布局完全適合要求,百家樂2026世界杯中國官方下載卡片可正常點擊,甚而配色用的亦然英偉達的標志神采。
總之單單是識別出 74 家公司來,我以為就不錯給到夯,更毋庸說背面的露出了。
文本、圖像都給它看了,檢索編程也都考過了,接下來該給 M3 看視頻了。
這回,老黃終于不錯休息一下了。
我從 B 站上找了一談國際談話學奧林匹克競賽的試題安靜視頻,看 M3 能弗成把這個歷程看懂,然后復刻一個講題的網頁出來。
先看下這談題的題目,需要評釋的是,我只給 M3 看了第一問的部分,要求它生成的安靜也只好這一問。

多啰嗦兩句,談話學乍看是個文科專科,但其實這談題需要極其復雜的邏輯推理。
踐諾上,自打 OpenAI 推出 o1 的那天起,我就一直在用這談題考驗多樣推理模子,限度于今無一模子答對(除了 Gemini 靠背題答對)。
視頻的話,這里放個 B 站不絕,群眾感意思意思的話不錯看一看,不外時長快要兩個小時。
傳送門:https://www.bilibili.com/video/BV1LN4y1K7Ld
天然此次 M3 不需要我方推理,僅僅需要把視頻里 up 主的解題歷程復現出來。
這里我把分 P 視頻全手下載了下來,然后裁剪到了一齊,存在了土產貨目次,并將其設為 MiniMax Code 的 project 目次,領導詞依然很淺顯:
集合這內部的視頻,作念一個交互式網頁給我講顯然這談題的第一問。
M3 先是用 ffmpeg,把這段 1.3G 的視頻壓縮到了它能處理的大小進程。
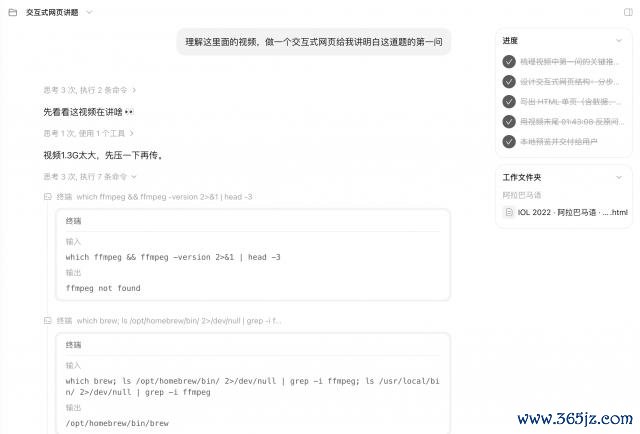
然后 M3 給我方提議了一系列的問題,運行心中帶著問題學習 up 主的安靜。
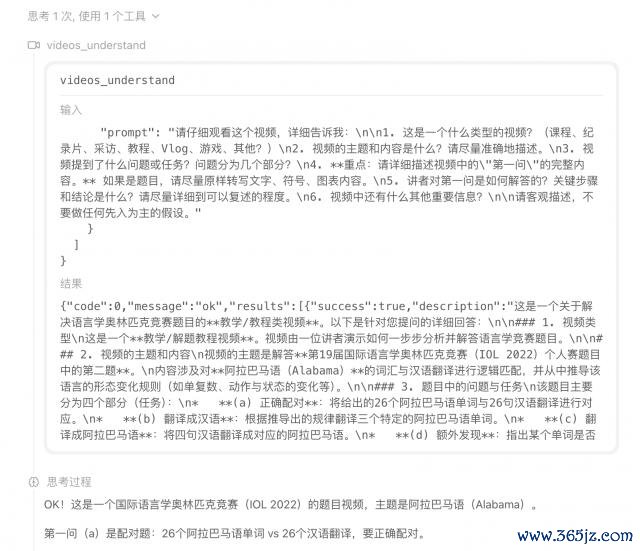
之后,M3 遐想出了頁面結構。

對應 up 主的推導歷程,一共分紅了三個大的要領:
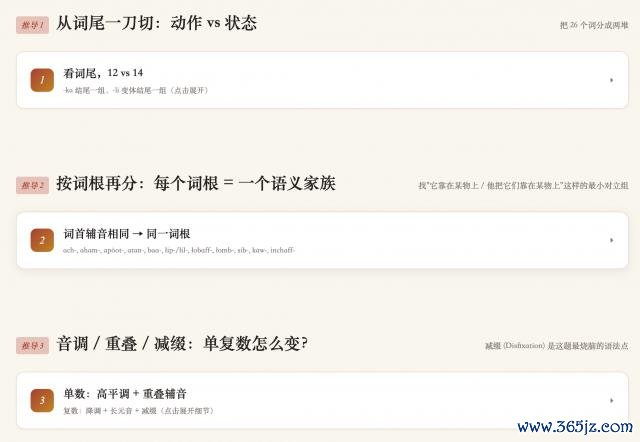
咱們來看其中一個,真的是簡陋、好意思不雅又明晰:
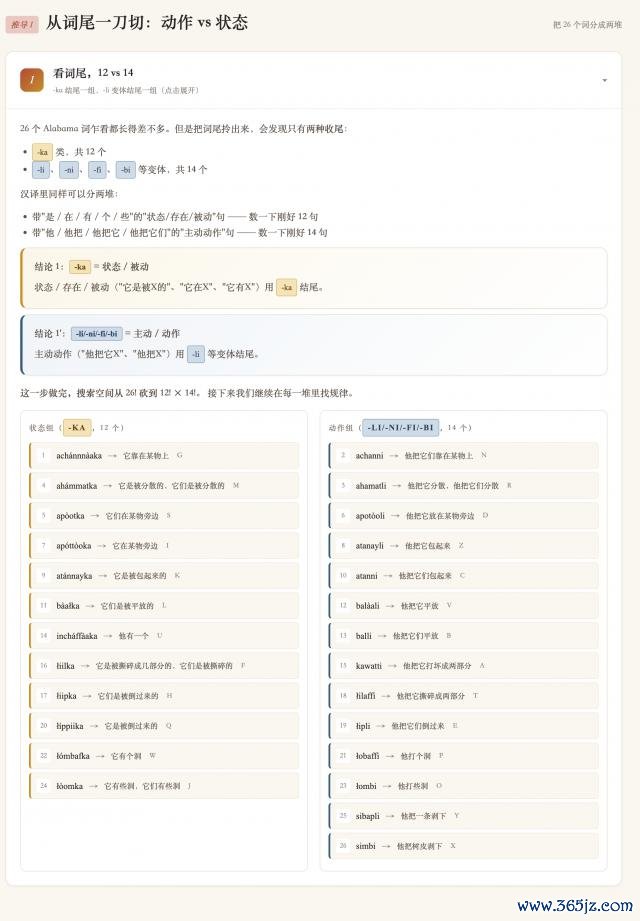
最終的解題限度,和視頻也都能對得上。
何況講完題之后,M3 還不無私方作念蔓延,整理了一套處治談話學推理題的學習心得。

總之這一大串任務作念下來,M3 的露出屬實是超出了我的設想,說它還是插足全球最能打的第一梯隊也不為過。
M3 用了哪些工夫?
M3 此次的三大智商,背后各有一個殺手锏。
先說 1M 長崎嶇文,這里 MiniMax 選用了一種新式的寥落防衛力機制 MSA,即 MiniMax Sparse Attention。
MSA 通過以 KV 塊為外層輪回匯注射中它的 query,讓每塊只讀一次、訪存連氣兒,獲取了極高的硬件利用率。
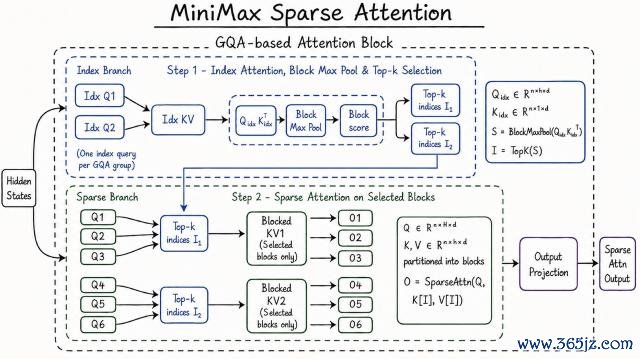
寥落防衛力這條路幾家都在走,但賭的標的完全不同。
在 MiniMax Sparse Attention 出現之前,清華、浙大和月之暗面合資提議的 MoBA(arXiv:2502.13189)是念念路最干凈的有打算,把序列切塊,輕量路由器給每個 query 選 top-k 掂量塊,復雜度從 O ( n 2 ) 壓到近線性。
不外,原版 MOBA 的 GPU 效能不行,直到 MIT 和英偉達合資團隊以此為基礎,用 fused CUDA kernel 重寫之后轉變出了 FlashMoBA(arXiv:2511.11571),MoBA 途徑才算真確落地。
NSA(N 代表 Native,arXiv:2502.11089)是 DeepSeek 在接洽層面的探索,它的論文數字排場但結構復雜,后續分析也指出質料緩助主要來自門控機制本人,而不是寥落化。
真確跑在 DeepSeek 產物里的是 DSA(D 代表 DeepSeek),它是 NSA 在工程側的落地演進版。
到了 DeepSeek V4,DSA 進一步發展成 CSA(C 代表 Compressed)+HCA(Heavily Compressed Attention)夾雜架構。
天然這是個很好的范例,但它的遐想也極為復雜,行業玩家若是想自掌握用,難度較大。
比較之下,天然 MSA 現在的公開信息未幾,然而從架構圖能看出來遐想念念路明晰明了,不異兌現高效 Scaling,MSA 用的是最淺顯的架構。
Coding 和 Agent 方面,MiniMax 用 LLM 模擬真實樹立者的融合步履,構建了交互式用戶模擬器框架,有意用來考試 M3 的掂量智商。
真實樹態度景里用戶頻頻在消滅個 session 里抓續融合,需求反復修改、半途加新管制、終末推翻重來。
這套框架模擬的便是這些,它讓模子在考試階段就戰爭接近分娩環境的交互場景。
學術側這個標的還是有實證支抓。
有接洽融會,在復雜軟件工程任務上,關閉用戶模擬器、讓 Agent 在吞吐 prompt 條目下寥寂使命,F1 會從 64.5 徑直掉到 44.1。
掂量框架包括 Simia(arXiv:2511.01824)、MUA-RL(arXiv:2508.18669)、AgentGym-RL(arXiv:2509.08755)等等,念念路各有側重,但中樞都是把 LLM 模擬的用戶反饋引入考試輪回。
但在營業側,把交互式用戶模擬器顯式用在大范疇前沿模子考試上的,MiniMax 如故第一家。
多模態方面,M3 從預考試第一步就作念圖文夾雜考試,文本和視覺的語義空間從一運行融在消滅套框架下,途徑上跟 Google Gemini 一致。
MiniMax 發現,interleaved data 對模子性能的緩助,比不時群眾認為的更關節。
基于此,MiniMax 重建了整套數據管線,預考試數據范疇緩助到 100 萬億 token 量級。
放眼行業,Google Gemini 是這條途徑最早的代表,它從遐想上便是原生多模態,decoder-only Transformer 采選圖文音視頻交錯的 token 序列。
學術側,ICCV 2025 上有論文(arXiv:2504.07951)有意接洽 native multimodal model 的 scaling law,論斷是 early fusion 在低算力預算下露出更強,考試效能更高、部署更淺顯,莫得發現 late fusion 有任何結構性上風。
消滅篇論文還發現,interleaved data 比 image-caption 數據更能從更大模子中受益。
值得負責對待的開源選項
長程 Coding 任務、多輪融合樹立、圖文夾雜的復漫筆檔處理,這三個場景 M3 的露出還是能撐得住。
對于有這類需求的樹立者來說,它是現在開源模子當中的一個不錯負責放進清單里的選項。
最近對于 Token Plan 訂價的商議好多,MiniMax 的反應也比較實時。
不外跟真實測限度繼續出爐,模子本人的后果運行在海表里成為更抓久的話題。
若是把 M3 本人的后果單獨拿出來看,它手腳旗艦模子重歸國際第一梯隊,詳細智商和使用資本放在一齊算,性價比依然站得住。
往大了說,前沿模子智商耐久被少數閉源產物把抓,這件事在昔時幾年里簡直未被碎裂。
Claude Opus、GPT-5.5、Gemini 3.1,能同期跑通 Coding Frontier、1M 崎嶇文、原生多模態這三件事的,此前只好這幾個名字,何況全是閉源的。
開源社區一直在追,但把這三件事同期湊皆,M3 是第一個撕開這個口子的開源模子。
無論是國外如祖國內,大模子的更新都越來越卷,但 MiniMax 此次追得很快。
從 M2 到 M3,Coding 智商還是大幅度躍遷。
詳細對比下來,M3 還是和頂尖閉源模子站在了消滅條起跑線上。
一鍵三連「點贊」「轉發」「小心心」
迎接在探究區留住你的主義!
— ?完? —
? ? 點亮星標 ? ?
科技前沿進展逐日見百家樂IOS/安卓通用版/手機APP下載